[논문 세미나] Learning Category-Specific Mesh Reconstructionfrom Image Collections
ECCV 2018, 578회 인용

Introduction
Single 이미지만 보고 3d shape, camera pose, texture 정보를 추출해보자.
이를 위해서는 해당 객체에 대한 데이터셋이 필요, 해당 데이터셋은 foreground mask와 semantic keypoint정보가 포함되어 있음. (이전에 소개한 SMPL에서 texture 정보를 추가로 예측하는 느낌..?)
일반적으로 3d shape를 예측하기 위해서는 학습 데이터에 3d ground-truth가 필요하지만, 본 논문은 2d 이미지 데이터셋만 가지고도 해결 가능.
또한 기존 논문들과 달리 texture를 예측하는게 가능하다는 장점이 있음.
Contribution
- Learning from an image collection
- Ability to infer texture
Proposed method
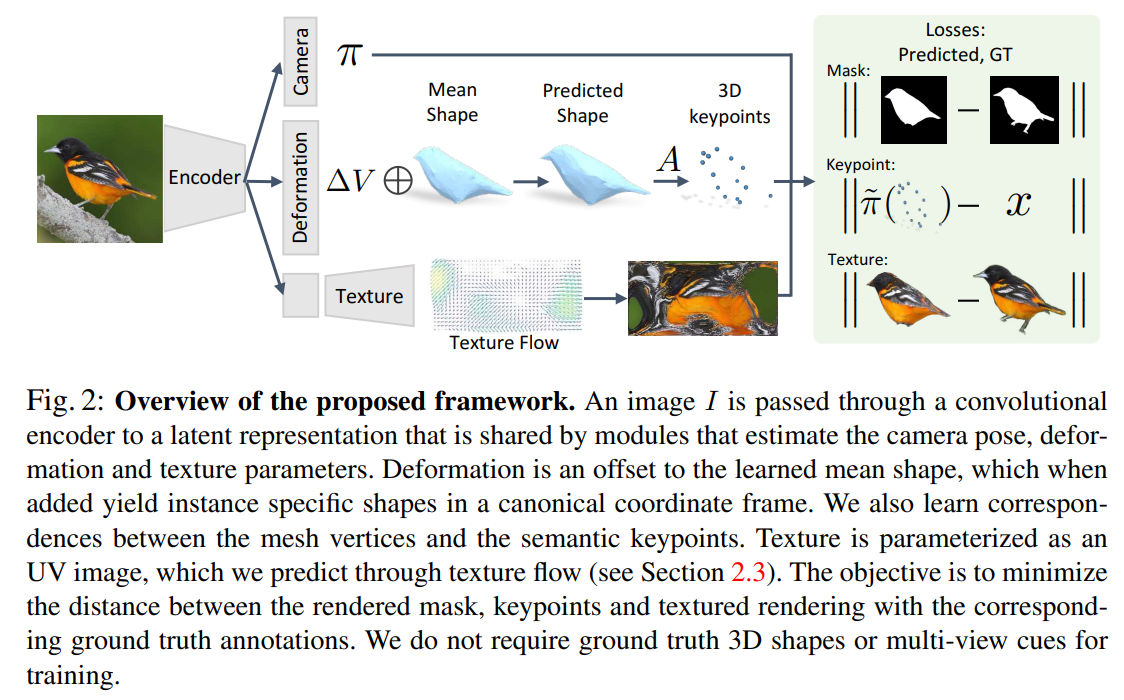
모델 구조를 간단히 살펴보면 크게 3가지로 나뉜다.
Camera parameter를 바로 예측하는 부분,
Deformation(delta_V)를 예측해서 3d shape를 예측하는 부분,
Texture flow를 예측해서 texture를 추출하는 부분이 있다.
(texture flow는 이전에 설명한 appearance flow의 3d 버젼같은 비슷한 느낌)
좀 더 자세히 설명하면,
카메라 parameter의 경우

scale, translation, rotation를 예측한다. (이전 논문에서도 항상 일관적으로 나왔던 parameter)
3d shape의 경우

카테고리별 평균 shape(V_bar)가 구해지고, instance별로 해당 평균 shape과 차이나는 정도(delta_V)를 예측하도록 모델을 구성한다. (SMPL에서도 사용하던 방식)
추가적으로 3d keypoint를 구하기 위한 파라미터(A)를 추가 학습한다. (instance-independent)


여기서 A의 역할은 주어진 vertex(V)와 연산을 통해 3d keypoint에 대한 위치를 나타낸다.
Texture의 경우 texture flow를 통해 구해지며, 결국 모델은 올바른 texture flow를 예측하도록 학습된다.

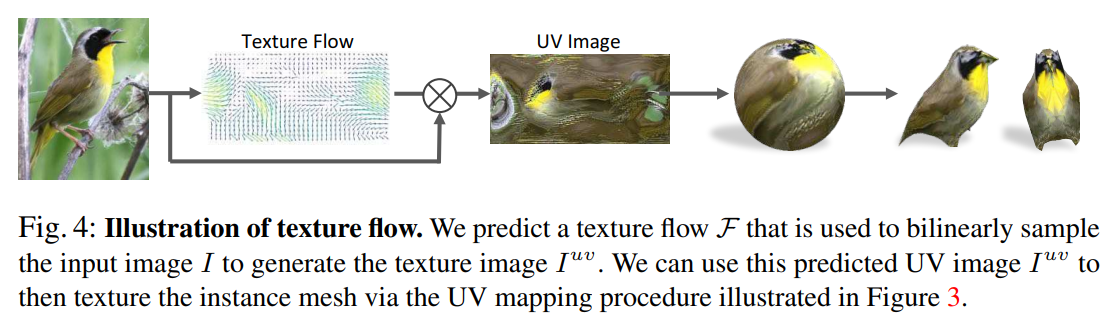
Texture에 대한 추가 설명(사실 이부분이 처음에 이해하기 어려웠음.. 지금도 완벽하게 이해하고 있지는 않음)
그림과 같이 우리가 구한 mean shape(V_bar)은 구 형태의 모델로 부터 구할 수 있음
(구 형태의 모델과 같은 vertex 개수 및 연결관계를 가지고 있음, 다른점은 각각 vertex의 위치가 다른 정도?)
따라서 구 형태의 모델에 해당하는 vertex의 texture값을 알고 있으면 이를 바로 mean shape 모델에 적용할 수 있음.
여기서 구 형태 모델의 texture값은 texture image로 부터 구할 수 있음.
(구 모양을 펼쳐서 평평한 이미지로 투영한 것처럼 보임)
결국 texture image -> sphere model -> mean shape -> deformation model 형태로 texture 정보가 전달 된다고 볼 수 있다.
여기서 texture image는 texture flow를 통해서 sampling된다.
이 부분은 이전 appearance flow와 동일한 컨셉으로 보임.
이후 loss 설명
먼저 학습 데이터셋을 다시 확인해 보면,
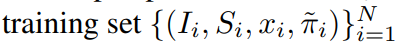
I: 이미지
S: instance segmentation
x: 2d keypoint locations
phi: weak-perspective camera
가 있다. 여기서 weak-perspective camera는 structure-from-motion(SFM)을 활용해서 구한다.
(이전에 세미나했던 non-rigid object 논문과 유사한 방식)
이제 loss에 대해서 알아보자
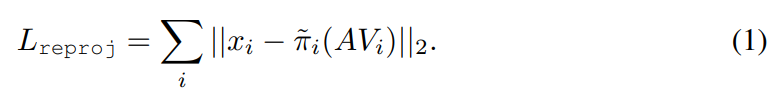
gt에 해당하는 2d keypoint와 모델로 예측한 2d keypoint와의 차이를 loss로 설정
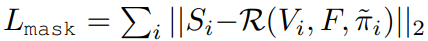
vertex로 segmentation mask를 표현해야 하는 경우, rendering이 활용되야 함. 하지만 일반적인 rendering 방식을 쓰면 2d domain(image)에서 3d domain(vertex)로 loss 전달이 안된다. 따라서 이를 가능하게하는 neural mesh renderer를 활용
(차마 이부분까지 읽어보기가..)

모델이 weak-perspective camera parameter를 예측할 수 있도록 어느정도 가이드를 줌
앞선 reproj, mask loss에 바로 predicted camera parameter를 쓰면 초기에 성능이 너무 안좋음
그래서 해당식에서는 weak-perspective camera parameter를 쓴다.

여기서 L은 discrete Laplace Beltrami operator(정확한 의미는 모름..)
해당 loss는 생성된 3d shape를 smooth하게 만들어주는 효과.
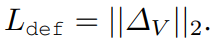
Deformation regularization 역할을 함. 즉 deformation값을 최대한 줄이면서, 학습되는 mean shape가 의미있는 값을 가지도록 유도함.

학습된 A행렬이 최대한 one-hot vector에 가까워지도록 유도, 즉 하나의 vertex가 하나의 keypoint를 표현할 수 있게 유도
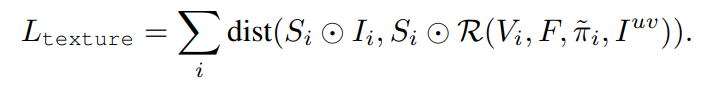
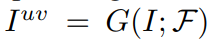

F는 texture flow를 의미, 이미지에서 객체에 해당하는 pixel color만 비교

Texture flow가 객체안에 있는 pixel 정보만 활용하도록 유도
Experiment result

Test set에 대한 visualization 결과를 보여줌

같은 3d shape model에 texture만 바꿔서 쉽게 transfer 가능

Deformation model을 사용한 경우가 mean shape만 사용한 경우보다 성능이 좋음.
그리고 gt 2d key point를 사용해 구한 sfm camera parameter와 모델이 예측한 camera parameter를 사용한 성능 비교 진행.
생각보다 성능차이가 크지 않다고 판단, 모델이 어느정도 camera parameter를 잘 찾는다고 보여짐.