[논문 세미나] Tracking People with 3D Representations
NeurIPS 2021, 21회
Introduction
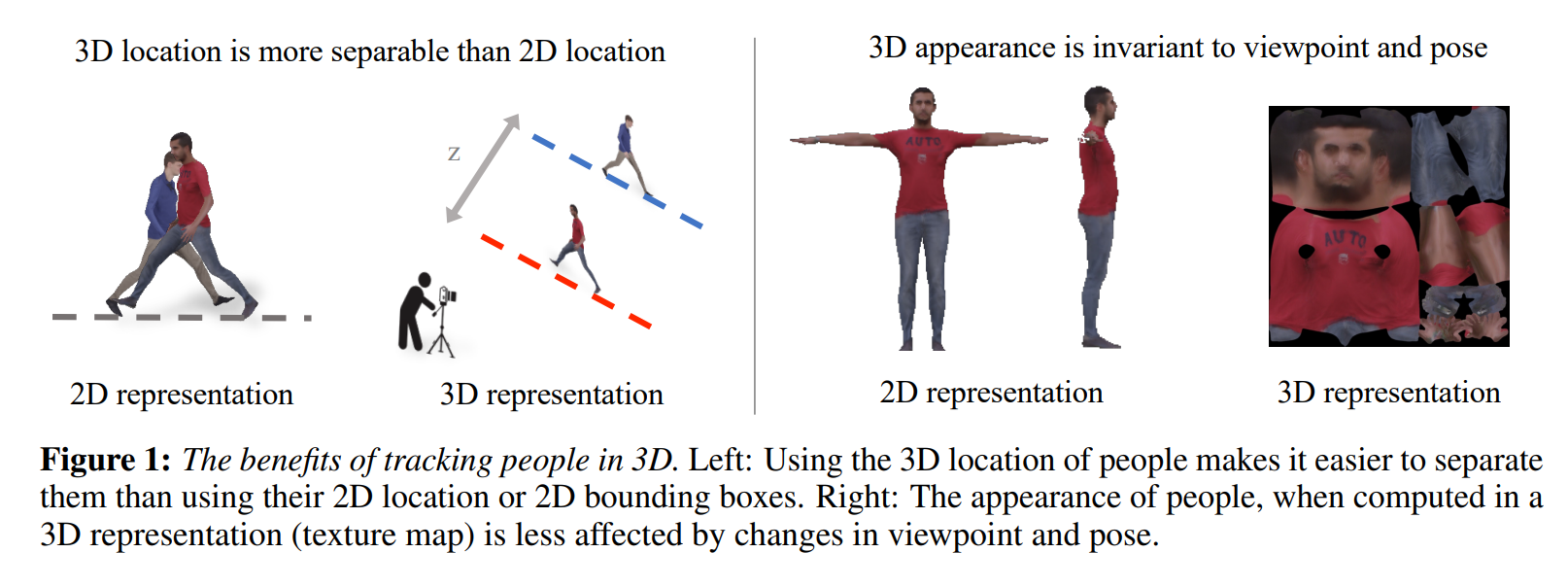
3d 정보를 활용한 People tracking 논문.
tracking 할때 2d 정보보다 3d 정보가 유리.
두 사람 사이에 overlap이 발생했을 때 2d 정보보다 3d 정보를 가지고 있는게 두 사람을 구분하는데 더 유리하다.
또한, 3d appearance는 2d appearance와 다르게 viewpoint와 pose 변화에 덜 민감하다.
Contribution
기존 HMR방식(SMPL모델의 pose, viewpoint를 예측하는 논문)에서 3d appearance 정보를 추가 예측하도록(이전 세미나에서 texture flow를 사용한 방식) 모델 구성
Proposed method
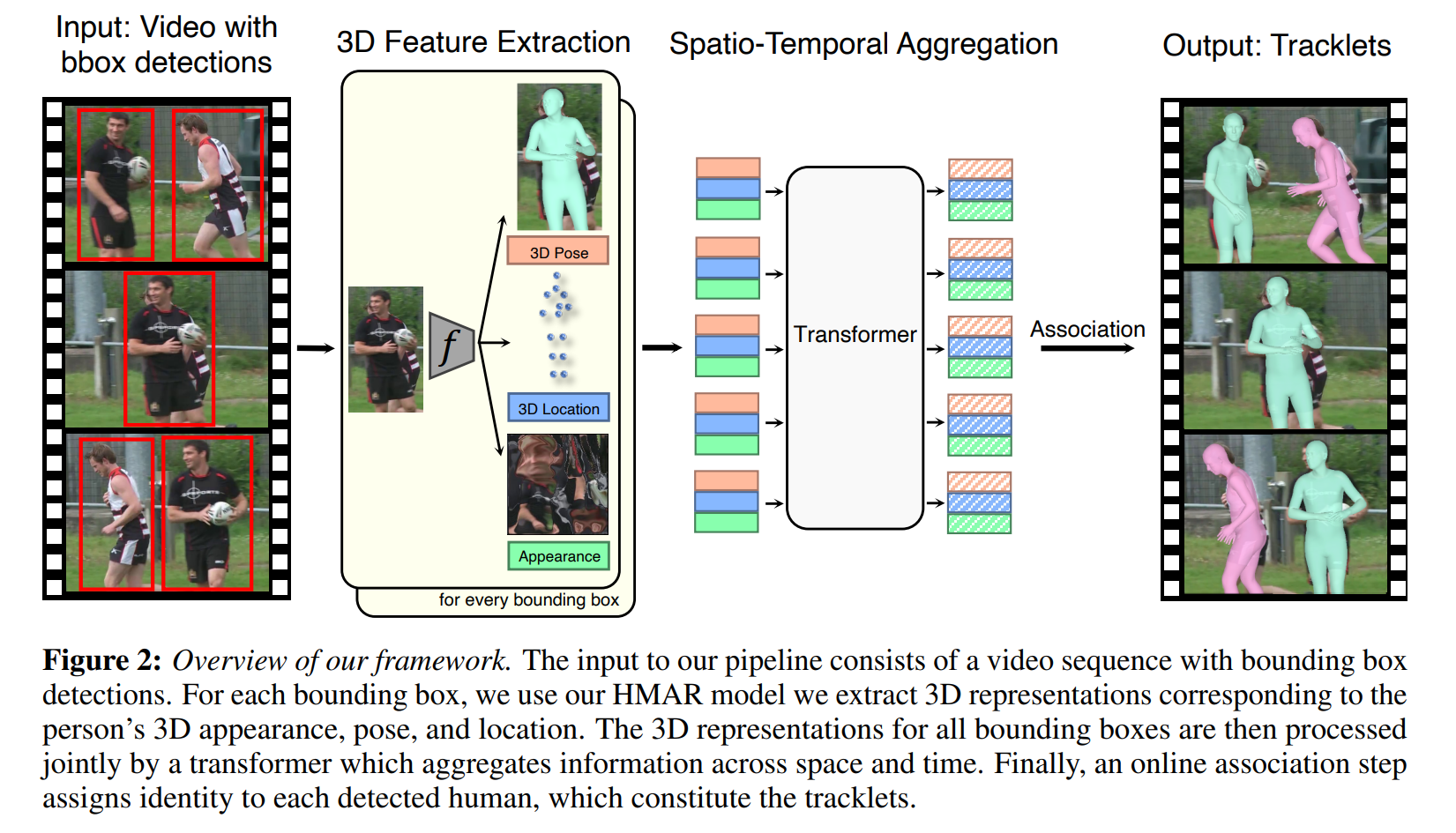
전체적인 구조는 아래와 같이 진행된다.
- encoder를 통한 3d 정보(3d pose, 3d keypoint, 3d appearance)추출
- transformer를 통과시켜 연속된 frame을 고려한 feature 추출
- 해당 정보를 바탕으로 association 진행, 검출된 사람에 id 부여
먼저 3d 정보에 대해서 알아보자
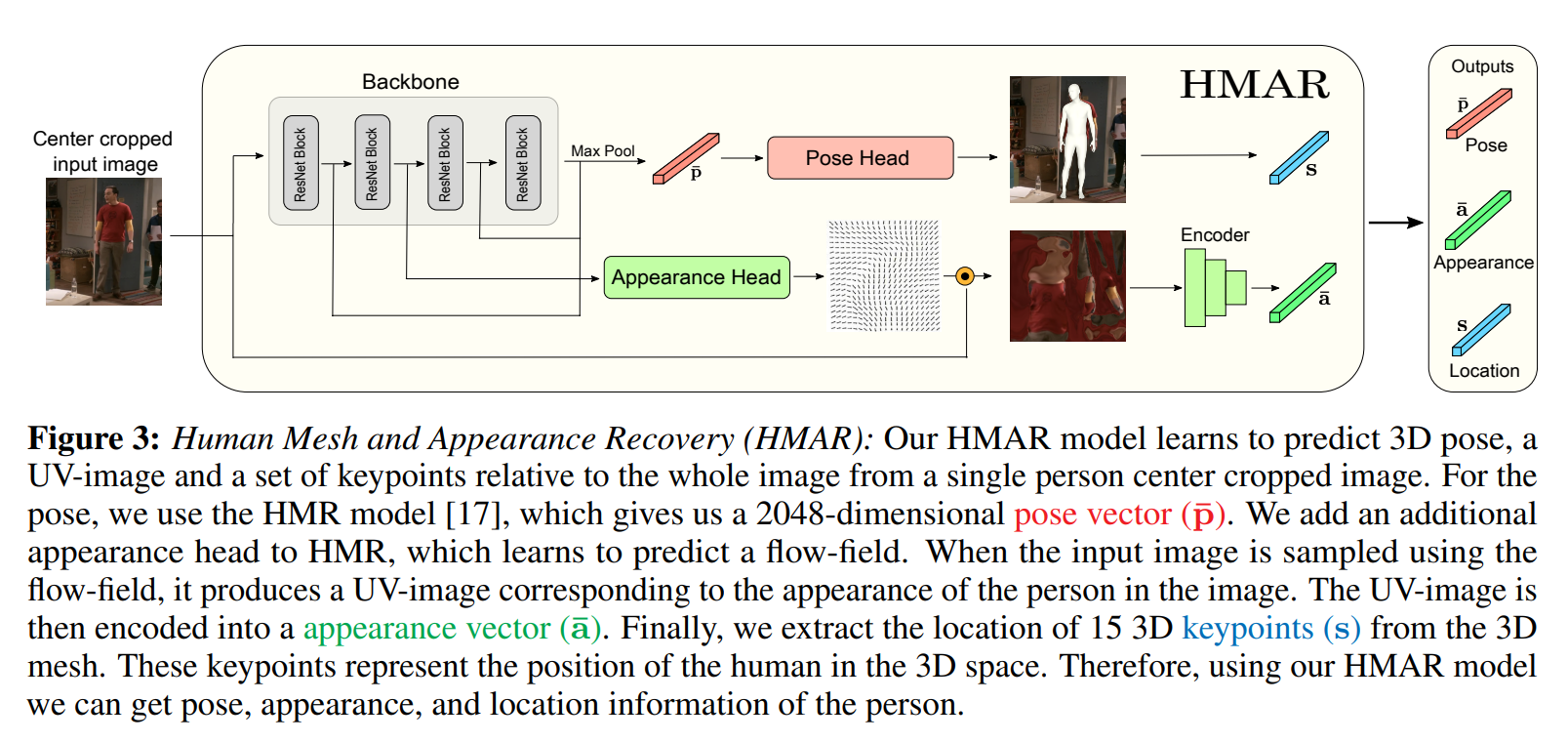
3d appearance:
texture flow를 통해 구한 texture image를 입력으로 사용.
여기서 encoder는 auto-encoder를 사용한다.
3d pose:
기존 HMR논문과 동일, 다만 여기서 활용하는 feature 정보는 pose head를 통과하기 전 feature 값(2048 vector) 사용
3d location:
우리는 crop된 이미지에서 3d keypoint의 좌표를 구할 수 있다.
이를 전체 이미지(global 좌표계)에 대한 좌표계로 변환시켜야 검출된 사람의 3d location을 표현할 수 있다.

HMR 방식과 비슷하게 카메라 parameter도 예측 가능하다, 해당 정보를 사용해서 3d global translation값을 구할 수 있다.
즉 2d bounding box 좌표 + 카메라 parameter를 사용해서 검출된 사람의 3d location을 예측한다.
다만 우리는 정확한 카메라의 focal length을 알 수 없기 때문에 3d location은 상대적인 값을 나타낸다.
(사실 검출된 사람들간의 위치 차이가 중요하지 실제 검출된 사람이 어느 위치에 정확하게 있는지는 알 필요가 없다)
1번 식을 보면 거리에 해당하는 정보는 검출된 bounding box의 크기로 유추하는 느낌이다.
(여기에는 사람의 실제 크기는 유사하다는 가정이 들어가 있다고 생각)
해당 모델에서 사용하는 3d location은 결국 global 좌표계에서의 3d keypoint 위치를 의미한다.
해당 정보는 Human mesh and appearance recovery(HMAR)로 구함

HMAR에 대한 결과를 보여줌
이후 transformer에 대한 설명
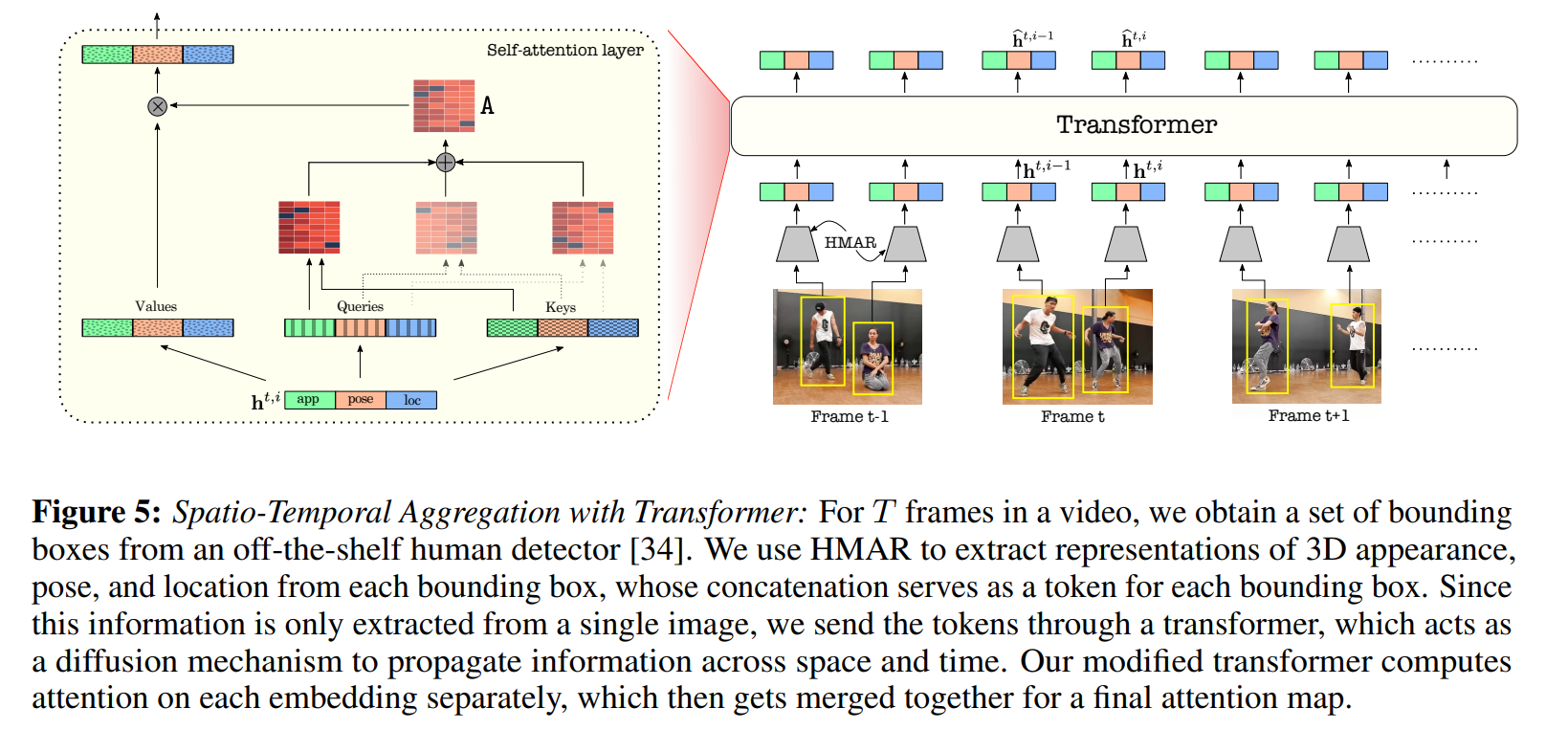
여기서 T frame에서 모은 사람들의 3d 정보를 transformer의 입력으로 사용

여기서 transformer의 역할은 같은 id끼리는 비슷한 feature값이 나오고 다른 id에서는 다른 feature값이 나오도록.
(contrastive loss와 유사)
ReID에서 사용하는 loss와 비슷.
이를 가지고 tracking algorithm 진행

여기서 매칭은 hungarian algorithm 사용하여 assignment 진행.
Experiment result
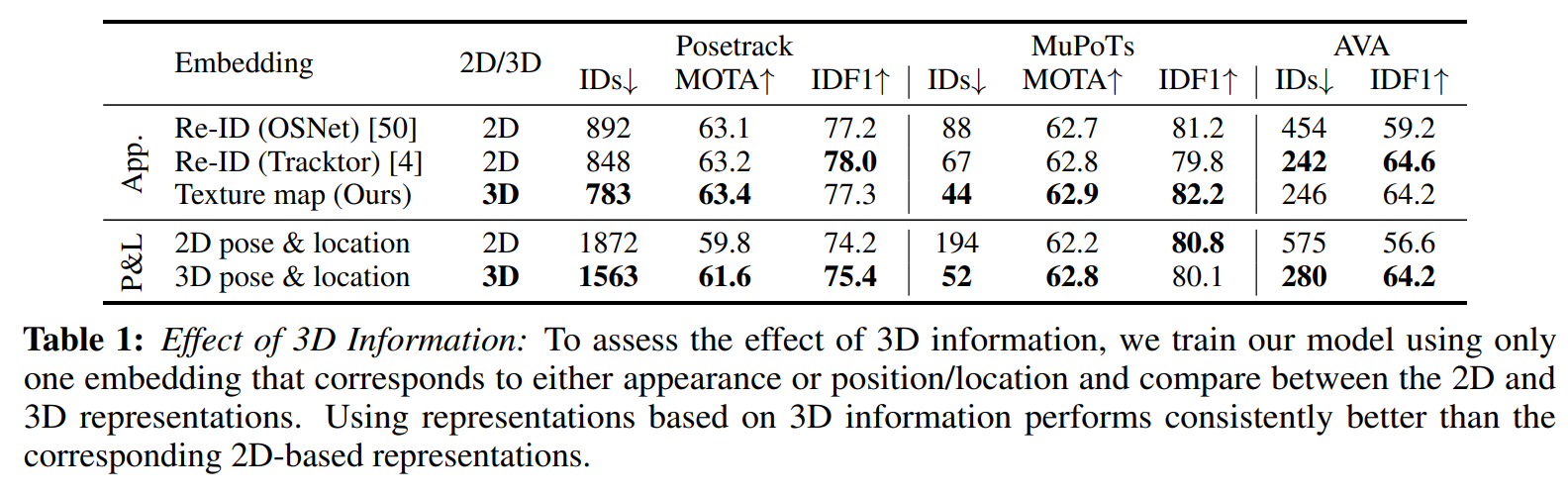
3d를 사용했을때 확실히 tracking 성능이 좋아짐
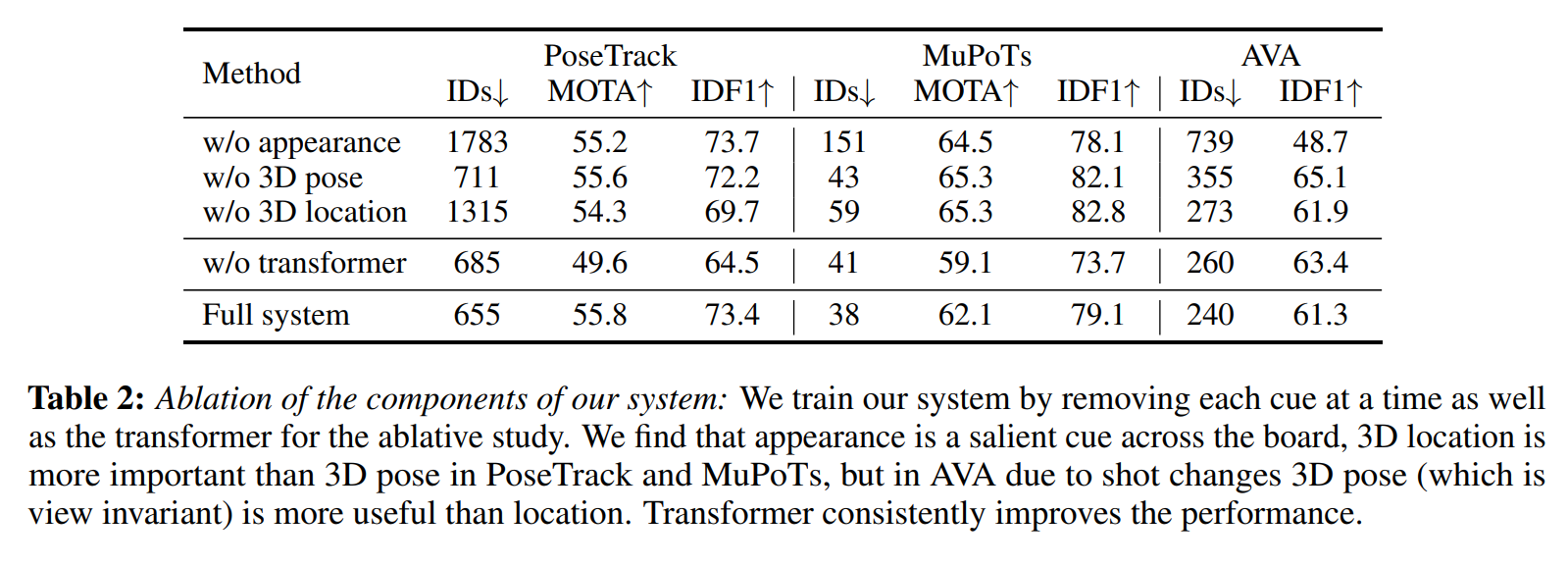
결과에서 알 수 있듯이 3d appearance의 영향이 매우 중요해 보임.
DB에 따라서 pose, location의 중요도가 달라짐.
(AVA dataset의 경우 장면 변화로 pose는 유지되지만 위치가 변하기 때문에 pose의 중요도가 더 큼)
transformer의 경우 전체적인 robustness를 증가시키는 역할.


다른 알고리즘과 비교 했을때 제안한 방식의 tracking 성능이 더 좋음.
Ours-v1의 경우 transformer을 사용 안함, Ours-v2의 경우 posetrack으로 학습한 transformer 사용.