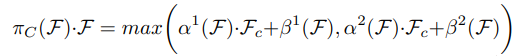Contribution 세미나
Dynamic Head: Unifying Object Detection Heads with Attentions
PaperGPT
2024. 4. 5. 15:34
Florence 논문을 보기 위한 두번째 논문

Attention을 scale-aware, spatial-aware, task-aware로 구분하여 고려, 이를 전부 고려한 attention은 아직 없었음
Feature pyramid를 L X S X C의 3d tensor로 변화하여 고려
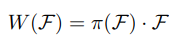
일반적으로 attention을 진행한다고 하면 Fully connected 로 진행, 연산량이 너무 많아짐

이를 3가지 형태의 cascade 구조로 구현, 연산을 효과적으로 함
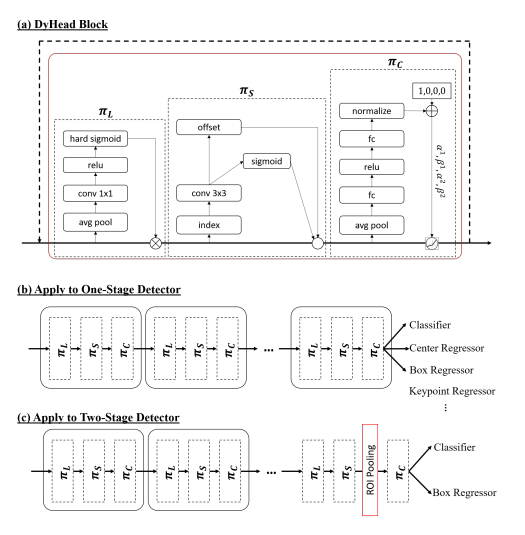
scale-aware의 경우 avg pool 이용하여 layer에 대한 weight 계산하여 적용
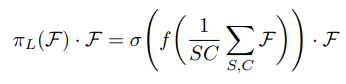
spatial-aware의 경우 deformable convolution 고려

task-aware의 경우 dynamic relu와 비슷한 컨셉 사용, 이부분은 좀 더 자세히 볼 필요가 있음
컨셉은 L x S 영역으로 avg pool하여 채널별 output 값을 활용하여 어떤 채널이 어떤 task에 영향을 미치는지 판단