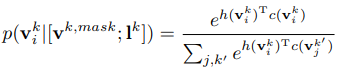An Empirical Study of Training End-to-End Vision-and-Language Transformers
Florence의 3번째 background 논문

VLM을 transformer을 활용해서 end-to-end로 효과적으로 학습하는 방법 제시
이 논문에서 알아낸것
- VLM에서 Vision transformer의 역할이 language transformer 보다 더 중요하다. 그리고 각각 task에서 transformer의 성능이 생각보다 VL task 성능의 좋은 지표가 되진 않는다.
- Cross attention이 multimodal fusion에서 중요함
- Encoder only VLP가 encoder-decoder model 보다 성능이 좋음 (VQA, zero-shot image-text retrieval 에서)
- Masked image modeling loss가 downstream task 성능 향상을 시키진 않는다.
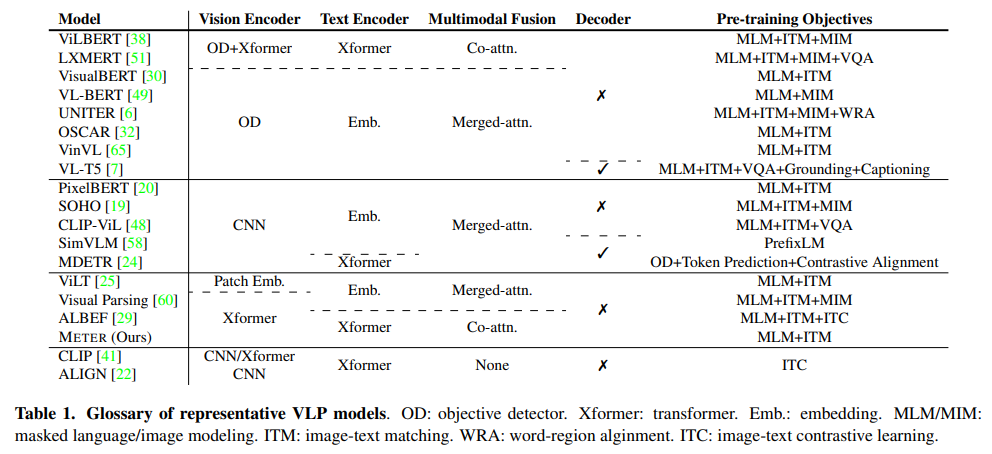
Vision encoder
일반적으로 ViT를 많이 활용, 이 논문에서는 다양한 backbone 사용하여 비교
Text encoder
일반적으로 BERT를 많이 활용, 이 논문에서는 다양한 backbone 사용하여 비교
Multimodal fusion
merged attention과 co-attention 사용

두가지 방식에 대해서 실험 비교
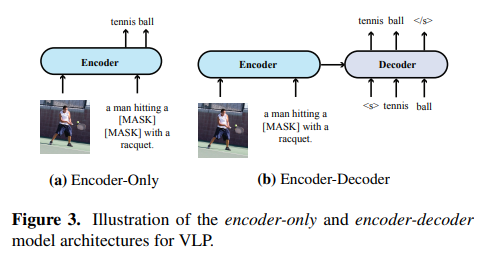
Encoder-only vs Encoder-Decoder
Pre-training objectives
Masked language modeling
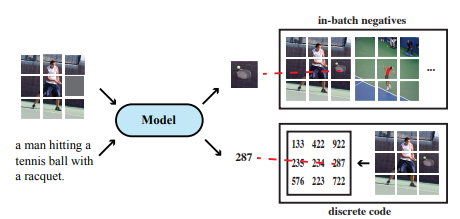
: Specifically, given an image-caption pair, we randomly mask some of the input tokens, and the model is trained to reconstruct the original tokens given the masked tokens l mask and its corresponding visual input v
Image-text matching
: Specifically, a special token (e.g., [CLS]) is inserted at the beginning of the input sentence, and it tries to learn a global cross-modal representation. We then feed the model with either a matched or mismatched image-caption pair <v, l> with equal probability, and a classifier is added on top of the [CLS] token to predict a binary label y, indicating if the sampled image-caption pair is a match.
Masked Image Modeling
초기 MIM은 MSE로 loss 계산