BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding

Open vocabulary쪽을 보다보니 text embedding 쪽을 안볼수가 없음.. 가장 유명한 BERT를 체크
BERT는 처음으로 bidirectional transformer을 사용

크게 2가지 step으로 구성: pre-training, fine-tuning
먼저 input에대한 representation
WordPiece embeddings를 사용해서 text를 token화 시킴 (약 30000개의 token vocabulary)
또한 사전에 정의해둔 special token 존재
문장의 처음은 항상 [CLS] token으로 시작, ViT에서 class token과 비슷한 역할
일반적으로 2개 이상의 문장이 입력으로 사용되기 때문에 문장과 문장사이는
[SEP] token으로 구별

여기서는 segment embedding 정보가 추가되어 있음
Pretraining의 경우 2가지 task로 구분
- Masked LM

약간의 augmentation을 통해 실제 학습
2. Next sentence prediction (NSP)

두가지 문장의 관계를 학습하기 위한 방식
연관 있는 경우 isnext 아닌 경우 notnext로 class 구별하도록 학습
추후 Question answering (QA)과 Natural language inference (NLI) 학습하는데 도움이 됨
Fine-tuning의 경우

For each task, we simply plug in the task specific inputs and outputs into BERT and fine-tune all the parameters end-to-end.
(c)의 경우 학습할때 paragraph에서 question에 대한 답변에 해당하는 문장의 start 및 end point 지점을 예측하도록
(d)의 경우는 자세한 설명이 없어서 나중에 한번 봐야할듯..
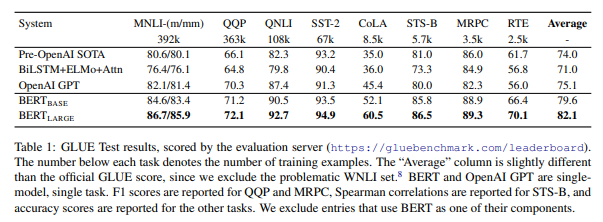
groundingDINO에서는 BERT base 사용