Contribution 세미나
Prompt-aligned Gradient for Prompt Tuning
PaperGPT
2024. 4. 16. 10:35

기존 Coop의 문제
학습이 진행됨에 따라 generalization 능력이 떨어짐
augmentation 없이 많은 sample들에 대해 학습을 진행할 수록 성능이 떨어짐
즉 기존 coop에서 overfitting을 방지하기 위해 early stopping이나 data augmentation을 적용하는데 이로 충분하지 않다
이를 gradient 관점에서 해결해보자

Grad-CAM 결과를 참고
Domain-specific 정보는 overfitting 되어 객체뿐만 아니라 주위 배경을 보고 판단
일반적인 CLIP은 객체 위주로 봄
Domain-specific 정보를 ZS-CLIP 기준으로 parallel, orthogonal 방향으로 decompose 해서 특징 확인
orthogonal 방향은 general knowledge에 영향을 미치지 않음
parallel 방향은 경우에 따라 general knowledge에 반하는 방향으로 영향을 줄 수 있음

KL loss

제안하는 prograd
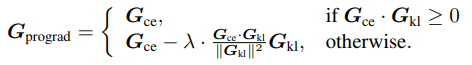
결론은 기존 CE와 KL의 방향성이 일치(90도 이내)하면 그대로 CE기준 업데이트
일치하지 않으면 orthogonal 방향으로 업데이트