Explicit Box Detection Unifies End-to-End Multi-Person Pose Estimation

Introduction
이전 세미나에서 PETR이 fully end-to-end로 pose estimation을 진행하면서 좋은 성능을 보여줬다. 하지만 본 논문에서는 PETR의 한계점에 대해서 설명하며 논문을 시작한다.
- Pose query로 한번에 각 사람별 keypoint를 찾으려는건 좀 무리가 있음 (semantically ambiguous라고 표현함)
- Pose query의 경우 초반에 random하게 초기화를 하기 때문에 학습 수렴 속도가 느려질수 밖에 없음
- Keypoint representation을 point로 고려하는건 contextual information이 부족함
(Deformable cross attention에서 reference point위주의 encoded feature를 보는 부분을 말하는 것 같음) - Global-to-global, global-to-local, local-to-local 사이의 interaction이 너무 복잡하게 구성되어 있음
(여기서 global는 person bounding box, local은 keypoint를 의미함, 사실 PETR의 경우 이러한 관계가 불명확하다)
본 논문에서는 이러한 단점들을 보완하는 구조를 제안
Contribution
- 간단하게 정리하면 DETR구조에서 keypoint를 예측하기 전에 person detection 정보를 최대한 활용해보자
- Key point도 person과 같이 box representation으로 고려한다
Proposed method
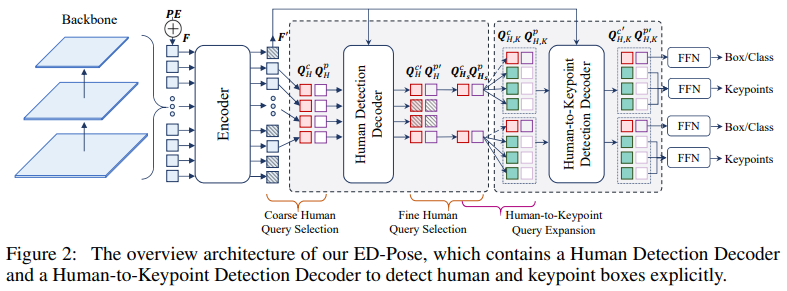
여기서 크게 2가지의 decoder가 사용된다. 각각의 decoder에 대해서 설명을 하면
Human detection decoder
우선 human detection decoder에 들어가기 앞서 query selection이 진행된다.
Encoder에서 나온 query들 중에서 classification score가 높은 top-N개를 선택한다.
(이는 DINO등의 DETR유형의 논문들에서 많이 사용하는 방식, 보통은 query에 간단한 auxiliary head를 연결해서 score를 계산한다)
이를통해 본 논문에서는 15K에서 900개로 줄임.
일반적으로 query는 content + position query로 구성되어 있는데, 여기서 position query는 content query로 부터 나오도록 (마찬가지로 간단한 detection head로 구성) 구성한다.
그리고 이를 human detection decoder에 넣어준다.

해당 구조는 DAB DETR과 매우 유사하다 (position query를 4d anchor box 형태로 가져감)
이렇게 가져가면 달라지는 점은 deformable cross attention 할때 sample point가 position query에 있는 anchor box(x,y,w,h)안에서 샘플링 된다.
즉 사람 검출에 있어서 좀 더 의미있는 영역을 중점적으로 보는 효과
이를 통해 구해진 output
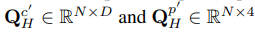
에서 마찬가지로 top-N개의 query를 선별 (900 → 100)
이렇게 선별된 query들은 이후 keypoint를 찾는데 사용된다.
Human-to-keypoint detection decoder
먼저 human query를 keypoint query로 확장한다.
확장 방식은 random하게 K개의 keypoint query를 만들고 이를 각각의 human query에 더해주는 방식을 사용한다.
keypoint의 position query도 human position query와 유사한 방식으로 구성한다. (content query를 FFN에 통과시켜서)
다만 keypoint의 width, height는 human box의 width, height를 입력으로 하는 weight matrix를 통과시켜 나온 결과를 사용.
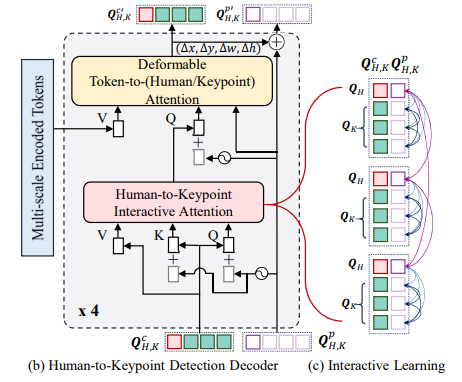
decoder 구성은 이전 human detection decoder와 유사하다.
다만 여기서는 self attention 부분이 조금 다른데, 그림과 같이
기본적으로 같은 person 안에서만 attention을 진행하게 되며, 다른 person에 대해서는 human query만 영향을 받도록 구성되어 있다.
즉 우리가 특정 사람의 key point를 찾는데 있어서는 다른 사람의 정보는 필요하지 않다라는 점을 보여주고 있다.
해당 decoder의 output이 최종 box 및 keypoint 결과를 보여준다.
Loss
이전 논문들과 유사하게 classification loss, human box regression loss, key point regression loss (L1 loss와 OKS loss 전부 사용)가 사용된다.
사실 이 논문을 보면서 가장 혼란스러웠던 점은 key point를 bounding box로 표현하는데 실제 loss는 key point 좌표와의 거리만 반영하고 있다는 점이였다. (key point의 gt box가 있는것도 이상하긴 함..)
즉 여기서 key point를 bounding box로 표현하는 이점은 cross attention에서 key point query가 예측한 box안 feature만 고려하기 때문에 전체 이미지를 보는것보다 더 좋은 효과를 가져온다고 생각된다.
Experiment
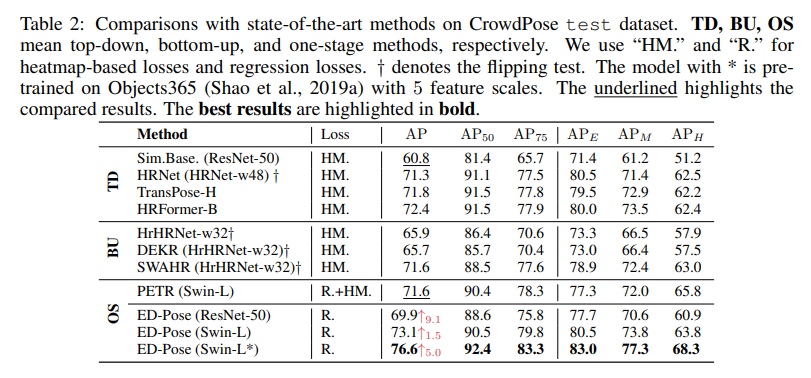
CrowdPose dataset에서는 HRNet보다 성능이 좋음
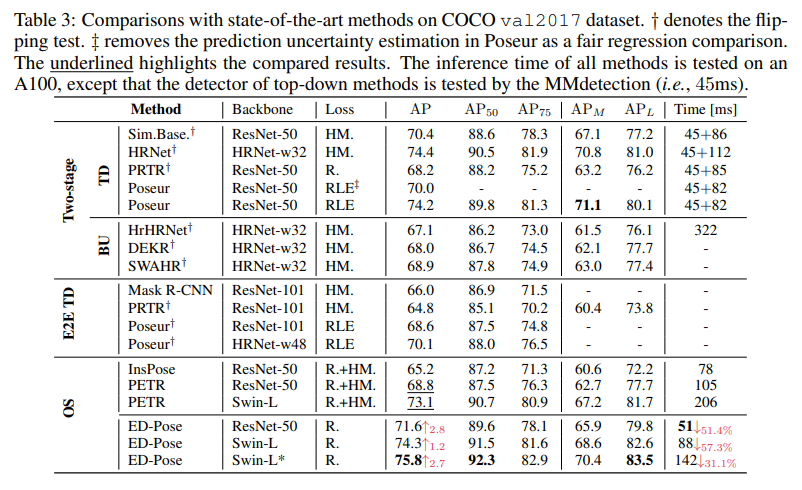
확실히 속도가 빠르고 높은 검출 성능을 보여줌

Keypoint box도 표현 (position query로 부터 나온 w,h를 표현한 것 같음)

detection에 대한 loss 유무에 대한 성능 비교

key point 표현 및 초기화 방식에 따른 성능 비교
None: 기존 (x, y)만 쓴 경우
Min: human box 크기의 1%로 초기화 한 경우
Max: human box와 동일한 크기로 초기화 한 경우
FFN: content query에 FFN을 통과시켜 구한 경우
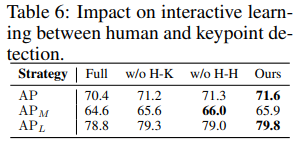
human query와 keypoint query 사이의 attention 방식에 따른 성능 비교
Full: 전부 attention 적용
w/o H-K: internal human-key attention 제외
w/o H-H: external human-to-human attention 제외

최종 선택한 query 개수에 따른 성능 비교