Unsupervised Prompt Learning for Vision-Language Models
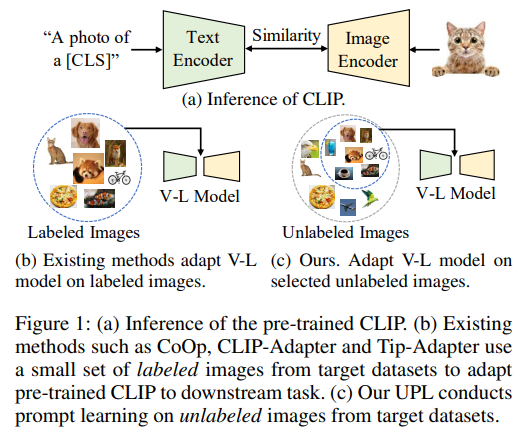
기존에는 few-shot learning이 주로 연구
해당 논문은 처음으로 unsupervised learning을 prompt learning에 적용
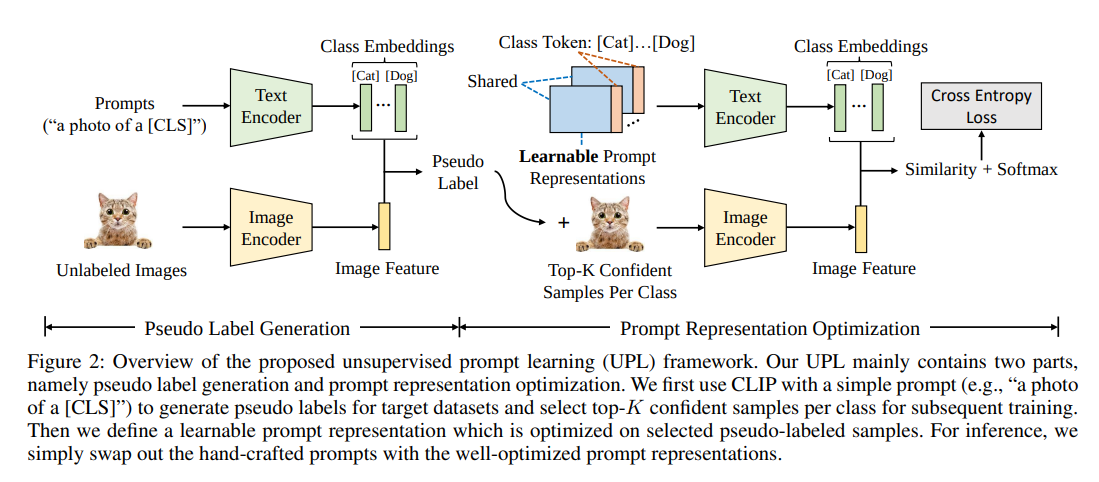
컨셉은 간단
class마다 top-K confident sample들을 추출해서 prompt learning 진행(coop과 비슷)
기존 pseudo label 만드는 방식처럼 왜 단순하게 confidence threshold로 추출하지 않는지에 대한 설명

confidence로 threshold해서 사용하면 class 불균형 발생, 또한 confidence가 높다고 무조건 pseudo label의 quality가 항상 좋진 않다
따라서 top-16을 사용

결국 class마다 confidence의 threshold가 다 다름

또한 기존 CLIP에서 backbone에 따라 class별 성능이 다 다름
따라서 해당 모델들의 Ensemble을 통해 pseudo label의 quality를 높임
실험
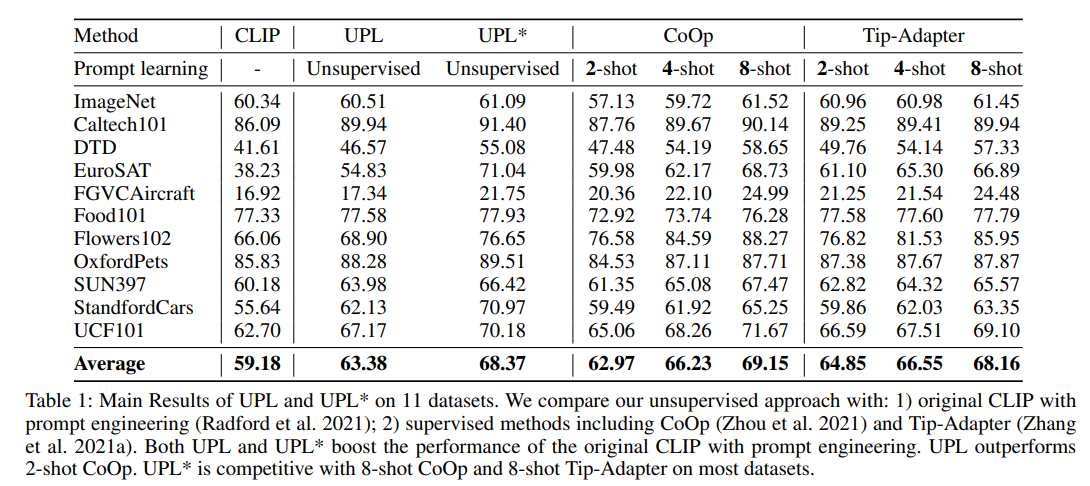
Unsupervised learning을 한 경우 기존 8-shot learning과 비슷한 성능을 보여줌

pseudo label 선택 방식에 따른 성능 비교
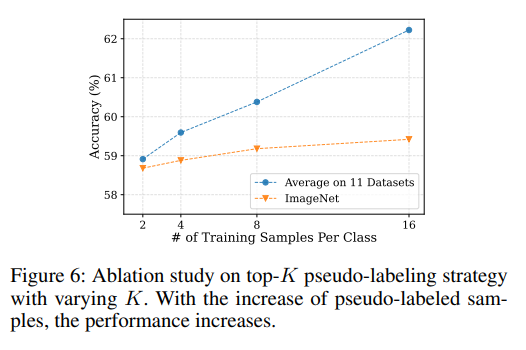
top-K에서 K에 따른 성능 비교 (K개수를 더 늘려도 되지 않나..?)

ensemble에 따른 성능 향상

또한 learnable prompts(길이 16)를 여러개(16개)사용해서 ensemble 진행
prompt를 학습할때 초기 값에 따라서 학습된 결과가 다름
(평균 성능은 비슷하지만, class별 성능이 차이가 발생)
따라서 inference할때 해당 모델을 ensemble 하면 성능 향상이 있음