LASP: Text-to-Text Optimization for Language-Aware Soft Prompting of Vision & Language Models

기존 Coop 방식은 text encoder 입력으로 learnable prompt 활용 → 너무 base class에 overfitting
learnable prompt가 그래도 text 정보처럼 보이게 (text embedding space와 가깝게) 하자
→ text-to-text loss 추가
전체 loss
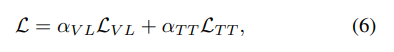
text-to-text loss

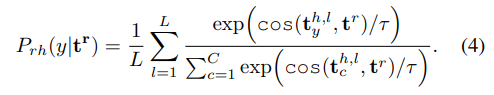
학습하려고 하는 learnable prompt는 t^r
text-to-text의 ground truth?는 L개의 hand-crafted prompt
(ex. a photo of a class)
text-to-text loss는 language-based augmentation 효과를 준다
→ regularizer의 역할 → overfitting 방지
추가적으로 data distribution shift 해결하기 위한 방안
기존 CLIP에서 학습했던 데이터 들과 few-shot learning에서 사용하는 데이터들의 data distribution이 다름
→ 이미지 encoder에서 layer normalization 부분만 fine-tuning
→ 이렇게 되면 기존 이미지와 text 사이의 misalignment 발생
→ text encoder 결과에서 bias 부분만 learnable vector로 학습하여 보정
이렇게 학습하게 되면 기존 Coop보다 더 discriminative class centroids 생성

class text embedding사이의 cosine distance를 비교했을때 LASP가 더 높은 distance를 가짐
또한 data-free distillation 가능
text-to-text loss를 계산할때 꼭 image-text가 매칭된 데이터가 필요하지 않음
따라서 novel class에 대한 class 정보를 사전에 학습할 수 있음
이러한 과정들을 여러 group으로 나눠서 진행
(multi head attention과 비슷한 컨셉)

Class가 포함하고 있는 서로 다른 특징들을 학습하기 용이하도록
실험
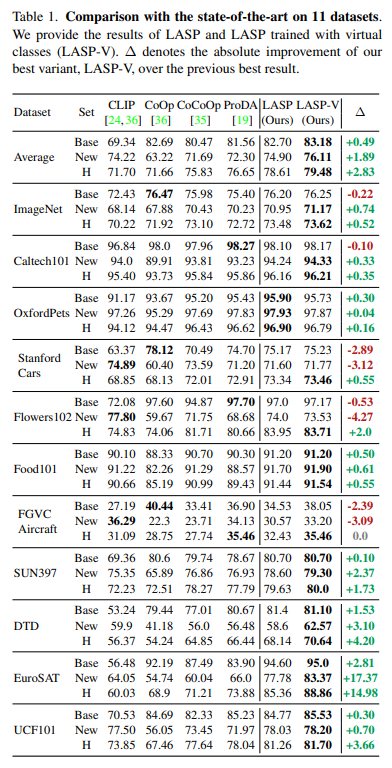
기존 prompt learning 방식에 비해 좋은 성능을 보여줌
(LASP-V 는 virtual class를 포함하여 학습한 경우)