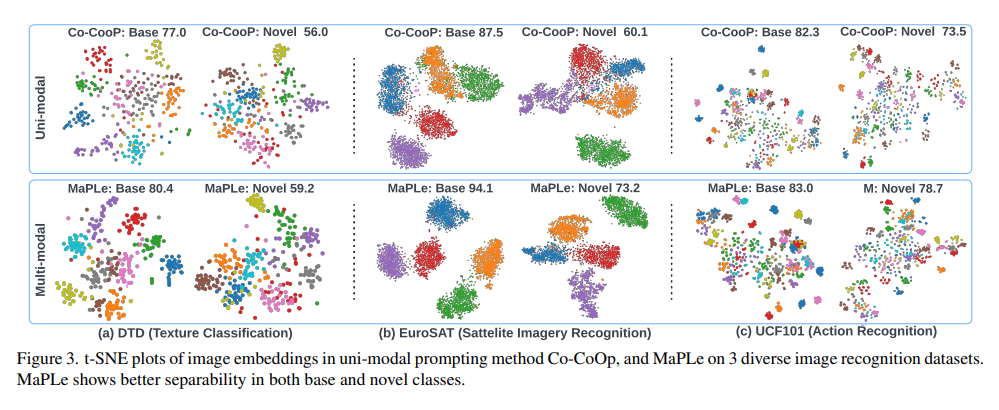
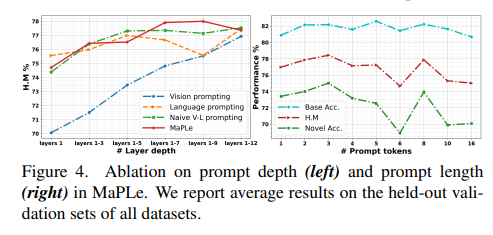
Contribution 세미나
MaPLe: Multi-modal Prompt Learning
PaperGPT
2024. 4. 16. 11:16

Multi-modal prompt learning을 제안
기존 prompt learning은 text prompt에 집중, 본 논문에서는 이미지 prompt를 같이 학습

해당 구조가 가능해지려면 CLIP의 backbone으로 transformer 구조가 사용되야 함
기존 방식 (vision)


기존 방식 (text)


multi-prompt(text)

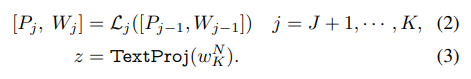
초기 J개의 layer에 대해서 learnable prompt 사용
multi-prompt(vision)

여기까지는 vision과 text사이에 정보 공유가 없음
Vision Language Prompt Coupling
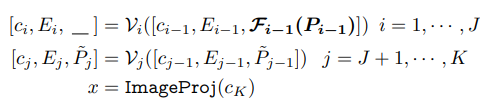
vision prompt가 text prompt에서 나오도록 변경하여 서로 연관성을 확보
contextual 정보를 align하기 더 쉬워짐