Multi-Prompt with Depth-Partitioned Cross-Modal Learning

Motivation: 이전에 발표했던 PLOT 논문과 유사, 단순히 multi prompt를 사용할때 global vision feature 결과만 가지고 비교하면 prompt가 이미지의 local 특징들을 반영하기 어렵다. 이를 해결하기 위한 방안 제시

각각의 prompt가 local 특징들을 반영할 수 있도록!
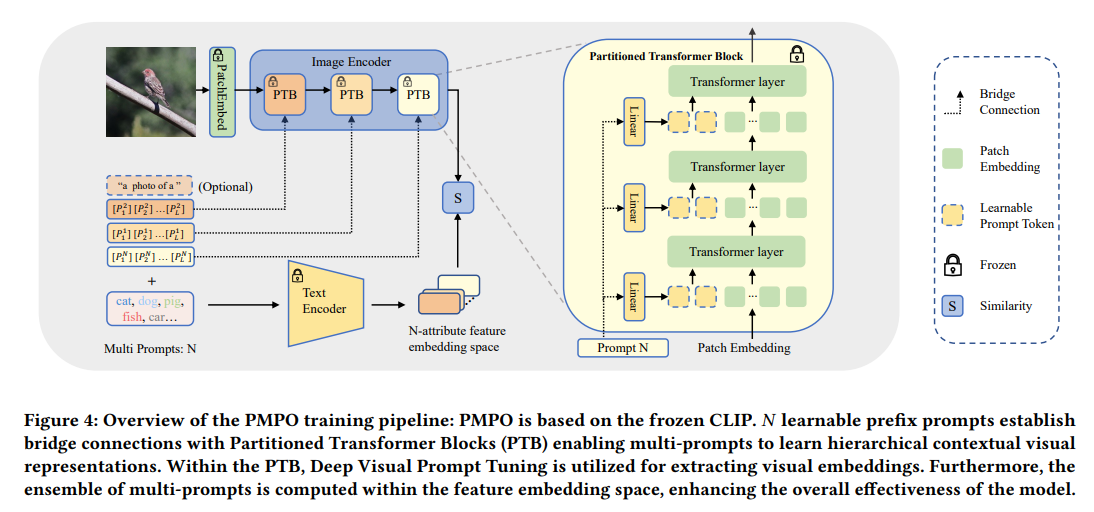
Transformer 구조를 활용
MaPle 논문: transformer 구조에서 learnable prompt를 넣어준건 비슷, 다만 uni-prompt 사용 (이부분은 사실상 완벽하게 uni-prompt는 아니라고 생각)
PLOT 논문: Multi-prompt 사용했지만 uni-modal (이미지, text 사이의 connection이 없음)
해당 논문은 multi-modal, multi-prompt 전부 적용
Transformer의 각각의 layer가 local 특징을 반영한다고 생각하여 부분적으로 prompt를 따로 적용
(이렇게 적용된 layer들을 partitioned transformer block으로 명칭)
Layer
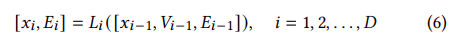
class probability

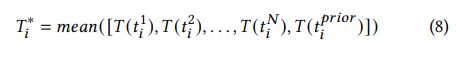
실험 결과
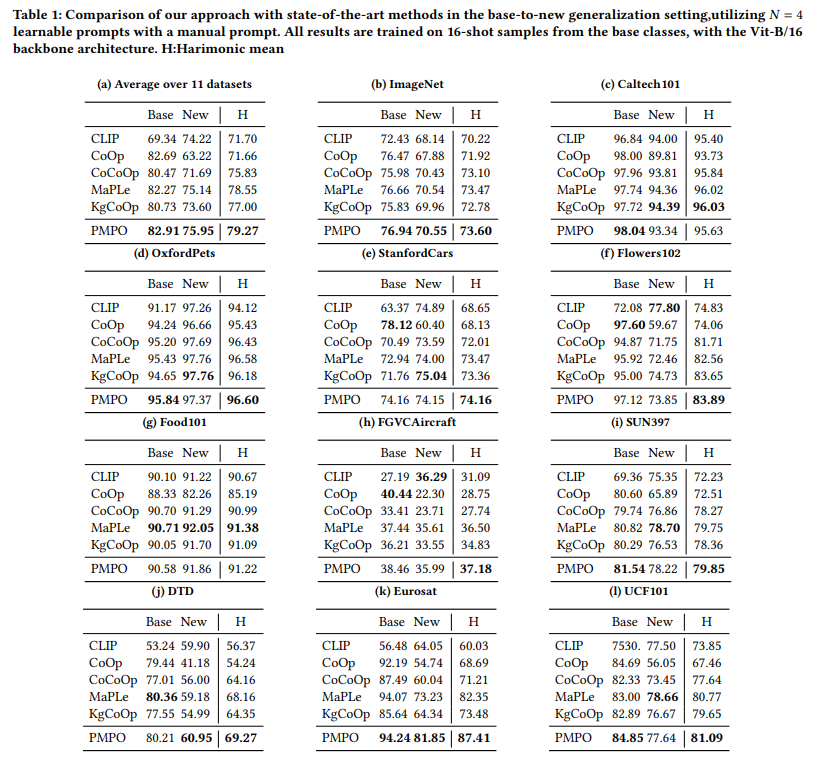
나름 높은 harmonic mean 값을 보여줌

Domain generalization 성능도 나쁘지 않음

Manual prompt를 같이 사용한 경우 성능 향상
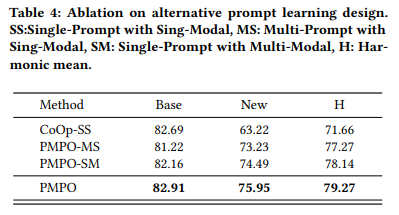
Multi-prompt multi-modal이 좋다

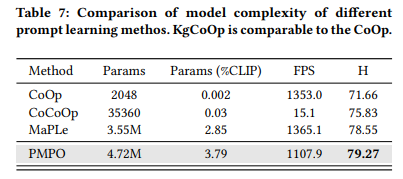
모델 complexity가 높아짐에 따라 낮은 shot에 대한 성능이 떨어짐,
즉 complexity에 따라 요구되는 학습 개수도 늘어남
Multi-prompt의 단점은 당연히 시간이 그만큼 소요됨
MaPLe이 파라미터 개수에 비해 빠른 이유는 learnable parameter가 layer 별로 연산이 적용되기 때문
(MaPLe는 text encoder 한번만 실행, PMPO는 N번 반복해서 평균내야 함)
다만 MaPLe이 CoOp보다 왜 빠른지는 모르겠음…