[논문 세미나] End-to-end Recovery of Human Shape and Pose
Introduction
이미지에서 3d human model(SMPL)을 잘 표현할 수 있는 방법에 대해서 서술한 논문.
이를 위해서는 이미지와 실제 사람에 대한 3d 좌표를 가지고 학습을 해야 원하는 정확도를 확보할 수 있음.
하지만 실제 이러한 데이터를 확보하는건 쉽지 않음.
따라서 일반적인 2d 데이터셋(2d keypoint만 있는 데이터)에서도 weakly-supervised 방식을 사용하여 2d-to-3d 연관성을 학습하는 방식을 제안.
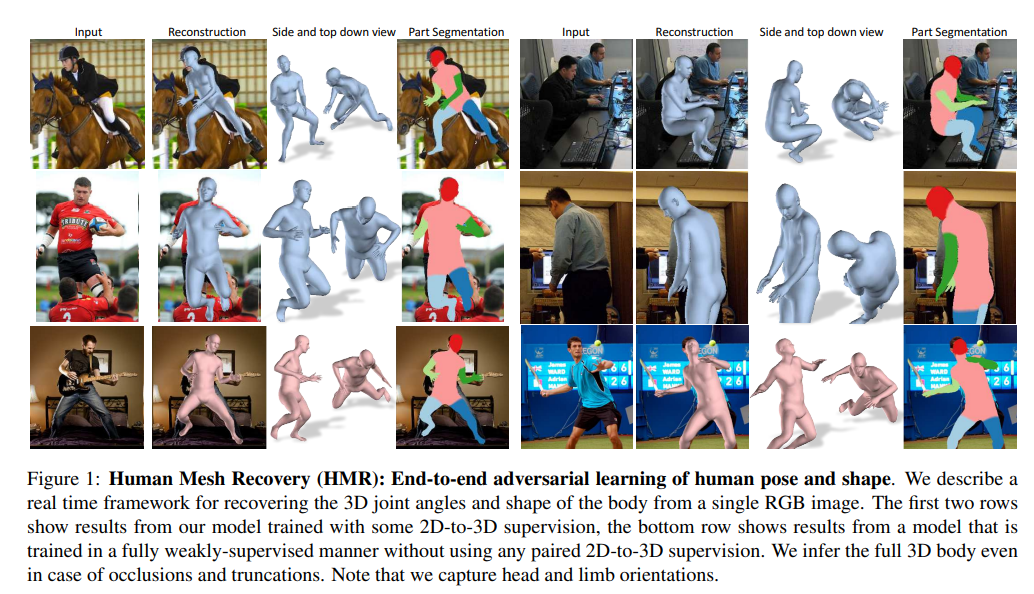
Fig. 1에서 첫번째, 두번째 줄은 실제 2d-to-3d 데이터셋을 사용하여 학습한 결과
마지막줄은 weakly-supervised 방식을 사용한 결과를 보여줌
Weakly-supervised 방식을 사용해도 준수한 성능을 보여준다.
(이렇게 찾은 3d 모델링은 사람에 대한 pose를 좀 더 디테일하게 표현할 수 있지 않을까..?)
또한 기존 방식들은 multi-stage 방식을 사용,
이미지에서 먼저 2d keypoint를 찾고, 이를 가지고 3d model parameter를 찾는다.
본 논문에서는 이미지에서 한번에 3d model parameter를 찾는 end-to-end 방식을 사용.
Contribution
1. 3D model parameter를 이미지에서 한번에 찾는 방식 제안
2. 2d skeleton이 아닌 3d modeling을 사용함으로써, 좀 더 복잡하고 적절한 pose를 표현하는데 적합
3. 모든 학습은 end-to-end로 진행
4. 어떠한 2d-to-3d pair 데이터셋도 필요없음 (weakly-supervised 사용)
Proposed method

모든 데이터는 2d joints 정보는 있다고 가정.
다양한 shape과 pose를 가진 3d modeling pool이 있다고 가정. (이미지와 pair할 필요는 없음)
Regression해야 하는 model의 output은 크게 SMPL parameter(pose, shape)와 camera parameter(s, R, T)가 있다.
다만 특이한 점은 R은 global rotation, T는 이미지 좌표계에서의 translation을 나타냄.
우선 예측한 SMPL parameter를 통해 3d keypoint를 찾을 수 있으며 이는 아래 식을 통해 2d keypoint로 변환할 수 있다.


이를 실제 2d keypoint와 비교하여 아래식과 같이 loss가 적어지도록 model을 학습하게 된다.
(사실 SMPL parameter는 그렇다고 쳐도, 카메라 parameter까지 학습이 되는게 신기함..)
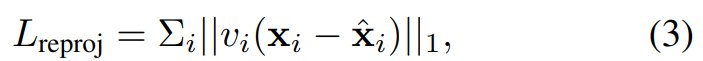
당연히 이미지에서 keypoint가 보이는 경우(v값이 1인 경우)만 loss에 반영한다.
하지만 여기서 발생할 수 있는 문제는, reprojection 에러가 줄어들어도 이는 모델이 생성한 3d human model이 부자연스러운 경우를 방지할 수는 없다는 점이다. (어떻게 보면 regularization 문제)
즉 모델이 생성한 SMPL이 자연스럽게 생성되도록 유도하는 loss를 추가한다. (GAN 컨셉과 유사)

추가적으로 Discriminator를 두어 모델이 생성한 SMPL이 기존 3d human modeling pool과 유사하도록 학습한다.
7번 식은 이를 만족하는 Encoder(model)를 학습

8번 식은 이를 만족하는 Discriminator를 학습
이렇게 되면 결국 Encoder를 통해 생성된 SMPL이 실제 사람처럼 자연스럽게 생성되도록 유도된다.
Experiment

실제 모델링 된 결과, 상대적으로 높은 error에서도 semantic한 정보는 어느정도 유의미함. 여기서는 MPJPE가 실제 visual quality를 잘 반영하진 않는다고 생각.

Reconstruction 에러는 rigid alignment이후의 MPJPE를 의미(semantic한 정보에 치중)
3d joints를 예측하는 기존 알고리즘들 보다 성능이 좋음, 더군다나 기존 방식들은 2d keypoint가 입력으로 필요하지만 제안 방식은 이미지에서 바로 찾을 수 있는 장점이 있음.
심지어 3d keypoint에 대한 gt 없이 학습해도 성능이 좋음.

Segmentation에 적용한 결과, 기존 알고리즘들 보다 빠른 속도를 보여준다.
(하지만 모델 구조를 보면 사람에 대한 roi가 있어야 동작하는것 처럼 보임..)

확실히 Discriminator가 없으면 부자연스러운 사람 형태로 modeling 되는 경향이 보임