DISC: Learning from Noisy Labels via Dynamic Instance-Specific Selection and Correction
CVPR 2023, 11회 인용
Introduction
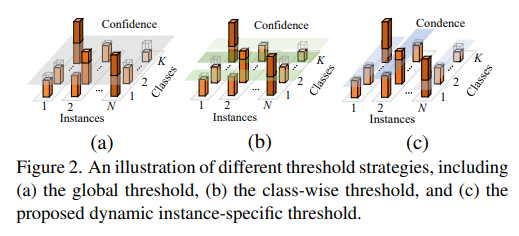
기존 방식들은 global, class-wise prediction threshold를 사용하여 noise를 걸려내고 있다면
본 논문에서는 dynamic instance threshold를 사용하여 좀 더 효과적으로 noise를 걸려낸다.

당연하게도 noisy한 data가 처음에는 prediction값이 낮지만 학습이 진행됨에 따라 over-fitting 됨을 알 수 있다.
Proposed method

2개의 augmentation 방식(weak, strong)을 활용
Dynamic selection으로 clean, hard, noisy set으로 나눔
noisy set의 경우 dynamic correction을 통해 pseudo label 수정 → purified set
해당 data로 학습
Dynamic Instance-Specific Threshold

instance 별로 max prediction history를 고려하여 threshold 설정
Dynamic Instance Selection
clean set

weak, strong augmentation에 대해서 gt label에 대한 prediction이 전부 threshold보다 높은 경우
hard set

clean set을 뺀 나머지중에 weak, strong 중에 하나라도 threshold 보다 높은 경우
나머지는 noisy set
여기서 clean과 hard set은 다른 loss를 적용
clean set의 경우 CE 사용

hard set의 경우 generalized cross-entropy 사용
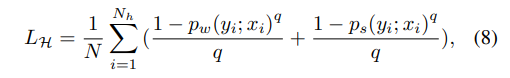
GCE의 경우 MAE와 CE를 혼합한 개념으로 CE보다 좀 더 robust regularization한 방식
Dynamic Instance Correction
noisy set의 label을 정제하는 작업


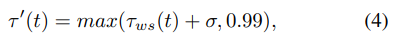
max prediction이 threshold를 넘어가는 경우 해당 prediction이 가리키는 class를 label로 설정
이렇게 최종적으로 구성된 3가지 set을 mix set으로 설정

해당 set에서 mixup 진행하여 BCE 계산
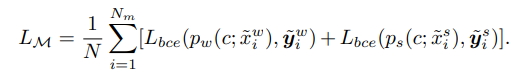

최종 loss


epoch에 따라서 mix set이 점차 증가 → data를 최대한 활용
Experiment result
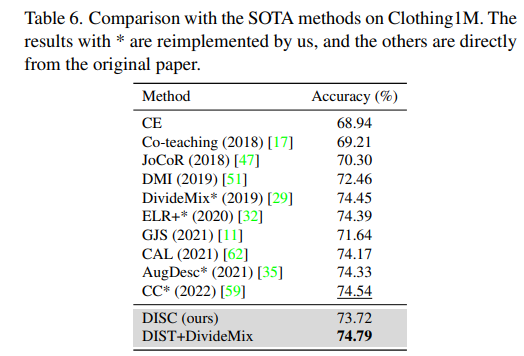
좋은 성능을 보여줌

모듈별 ablation study

selection 방식에 따른 성능 비교
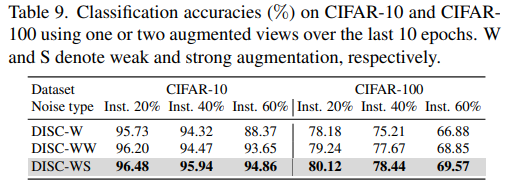
augmentation 방식에 따른 성능 비교