-
[논문 세미나] Knowledge Distillation with the Reused Teacher ClassifierContribution 세미나/Knowledge distillation 2024. 1. 28. 15:48
CVPR 2022, 95회 인용
Introduction
본 논문에서는 Simple knowledge distillation (SimKD) 방식을 제안하고 있다.
컨셉은 매우 간단, feature distillation 기반의 KD를 사용하는데 있어서 teacher classifier를 그대로 사용한다.
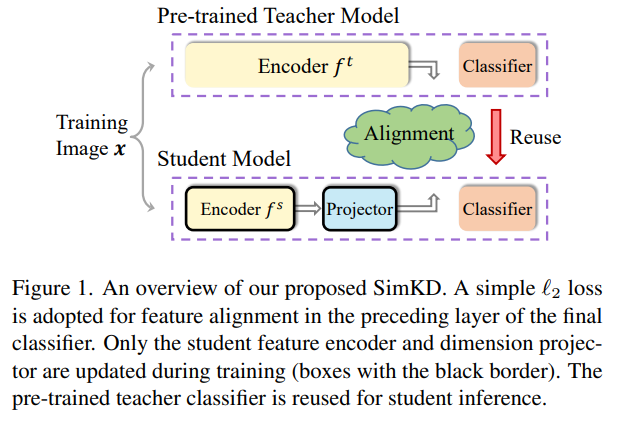
기존 방식과 비교하면
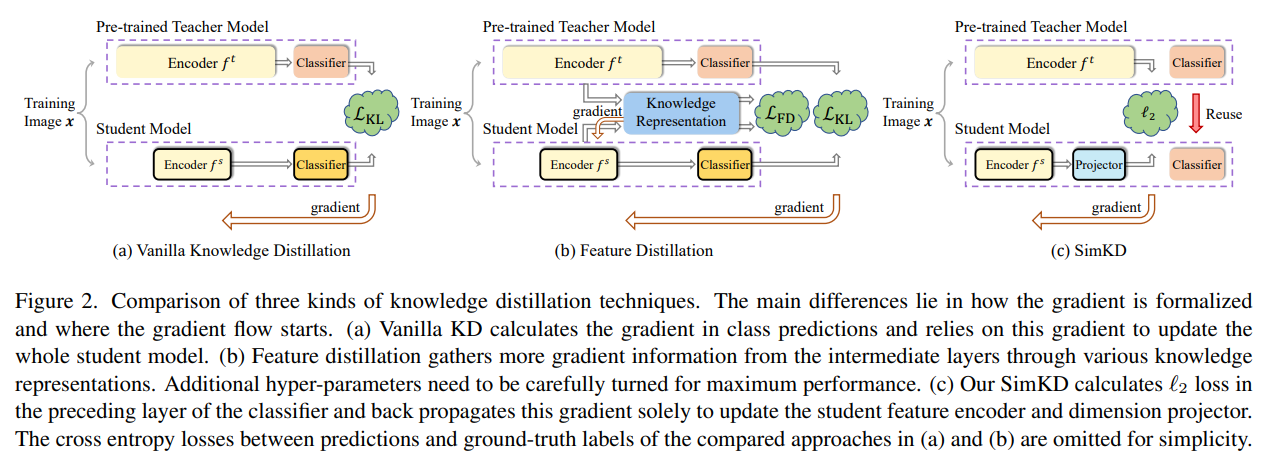
기존 feature distillation의 경우 일반적으로 logit distillation, cross entropy등 여러 loss를 고려해야 하고 이는 각각 loss 마다 weight를 조절해가며 성능 향상을 시킨다. (즉 hyper-parameter tuning이 필요하다고 생각함)
이와 달리 여기서 제안하는 teacher의 classifier를 KD에 그대로 사용하게 된다면, 단순히 feature distillation에만 집중하면 된다. (가정은 일반적으로 teacher와 student의 classifier 부분은 구조가 동일하다고 생각)
Proposed method
기존 softmax with temperature

기존 KD 방식
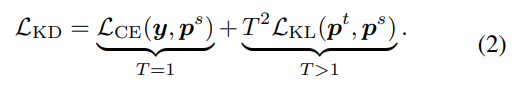
본 논문에서 가정하는 부분
학습 데이터에는 capability-invariant information와 capability-specific information 이 있음
capability-invariant information은 말그대로 학습 하기 쉬운 패턴
capability-specific information은 학습 하기 어려운 패턴
따라서 해당 정보는 deep layer에서 학습이 된다 -> 이는 곧 classification head부분에 주로 학습되어 있음
따라서 teacher classifier 부분을 student model에서 그대로 가져다 쓰면,
student model에서는 capability-invariant information에 집중하면 됨.

그래서 loss는 정말 간단함, projection 시킨 후 l2 loss

기존 KD의 경우 학습을 했음에도 불구하고 teacher와 student의 feature 차이가 발생
이와달리 SimKD의 경우 feature 차이가 상대적으로 적다
Experiment result
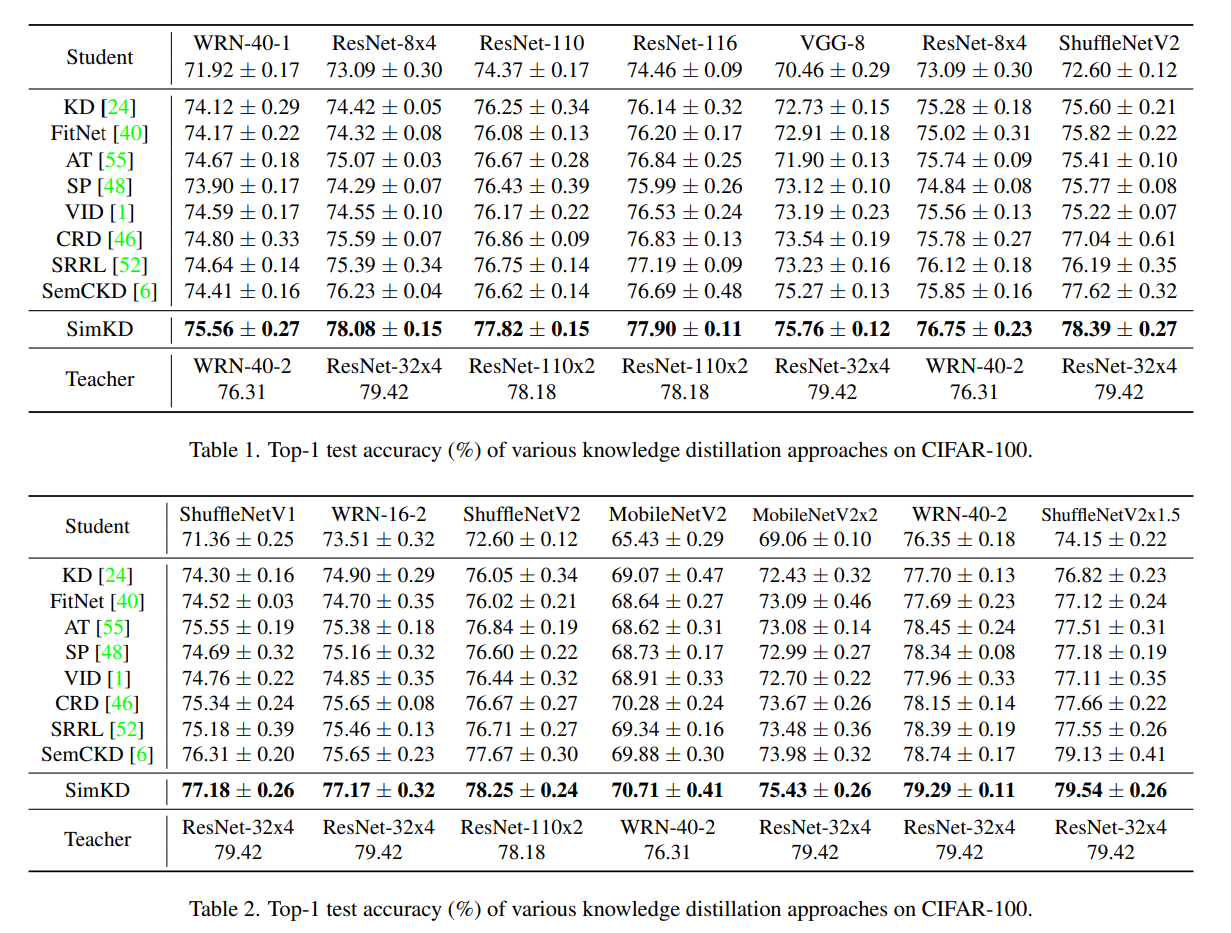
다른 KD 방식들 보다 좋은 성능을 보여준다.


logit KD와 SimKD와의 joint training 할때의 결과
student classifier로 같이 학습하는 것보다 teacher classifier를 가져다 쓰는게 성능이 더 좋다
즉 teacher classifier에 해당하는 정보가 student classifier에 전달 하기 쉽지 않다
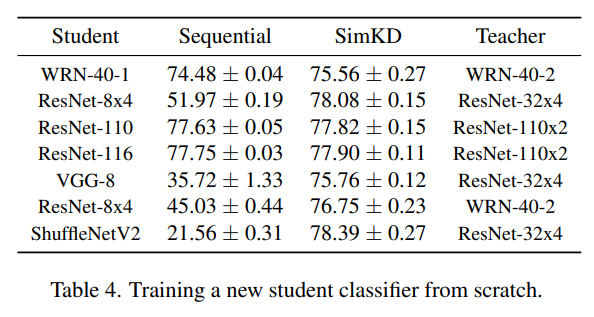
좀 더 극단적으로 테스트 한 결과
SimKD 방식으로 feature를 학습하고 해당 feature를 frozen시키고 classifier만 다시 학습한 경우
(Sequential)역시나 teacher classifier를 reuse하는 경우가 성능이 더 좋다.
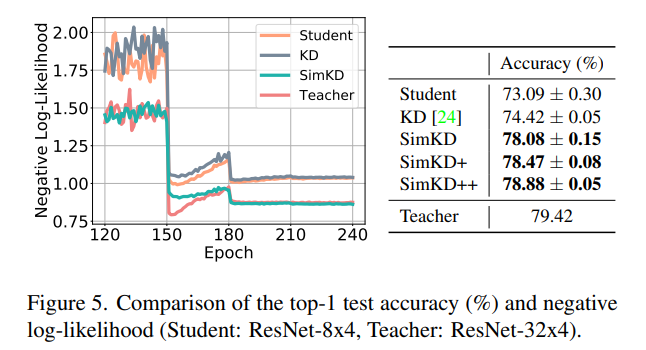
SimKD+, ++의 경우 마지막 teacher layer를 얼만큼 더 활용할지에 따른 비교
당연하게도 teacher layer를 많이 활용할 수록 성능이 좋아짐

Projection layer에 대한 성능 비교
'Contribution 세미나 > Knowledge distillation' 카테고리의 다른 글
[논문세미나] Knowledge Distillation via the Target-aware Transformer (1) 2024.01.21