-
Masked Generative DistillationContribution 세미나 2024. 4. 18. 11:08
ECCV 2022, 89회 인용
Introduction

Feature distillation에 관한 논문
기존은 단순히 teacher feature map과 동일하도록 학습 (L2 norm)
여기서는 student feature map에 random mask를 적용한 상황에서 teacher feature map과 유사하게 학습 하면 좀 더 semantic한 정보를 학습하는데 도움이 된다고 판단 (MAE와 비슷한 컨셉)
CNN의 특성상 feature map에서 인접한 pixel은 서로 정보를 어느정도 포함하고 있기 때문에 이와 같은 방식이 가능하다고 생각함
그림과 같이 실제 이렇게 학습한 경우 배경보다는 객체에 좀 더 attention이 잘 되는것을 보여줌
Proposed method
기존 feature distillation 방식

f_align은 teacher와 student의 채널을 맞춰주는 역할 (1x1 conv)

그림과 같이 random mask를 적용하여 masked feature 상태에서 distillation 진행
Mask 적용 방식

기존 student feature map에 아래와 같이 적용하여 매칭에 사용될 feature map 생성

최종적으로 아래와 같이 loss 설정
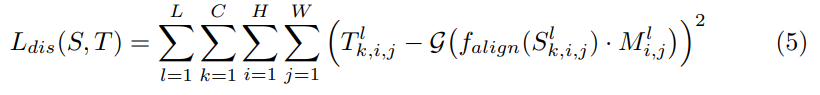
전체 loss
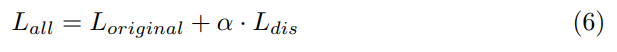
Experiment result

Feature + Logit 적용한 경우 좋은 성능을 보여줌
(다만 feature만 적용한 경우 KR이 더 좋아보임…)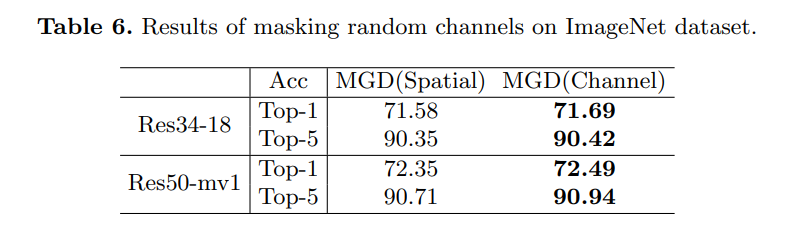
mask를 channel에 적용한 경우 성능이 더 좋아짐

teacher model에 따른 성능 비교
transformer가 teacher로 사용되면 성능향상이 적음
(비슷한 구조일수록 성능 향상에 도움이 된다고 함)

Generated feature에 사용 되는 kernel size 및 layer 개수에 따른 성능 비교
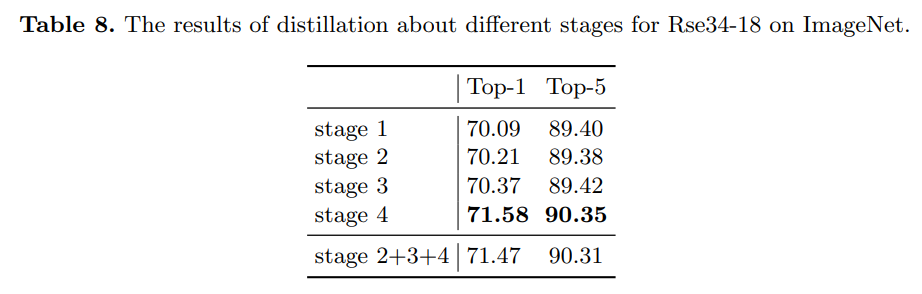
모든 stage보다는 마지막 stage만 KD를 사용했을때 성능이 좋음
(아무래도 random mask 역할이 어느정도 semantic한 정보를 layer가 포함하는 경우 잘 동작한다고 판단)
Hyper-parameter에 따른 성능 비교
아무래도 random mask 비율이 0.5이상 넘어가면 성능이 하락
'Contribution 세미나' 카테고리의 다른 글