-
MINILM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained TransformersContribution 세미나 2024. 4. 18. 11:17
NIPS 2020, 758회 인용
Introduction
Transformer에 특화된 KD 논문
기존 방식들과 비교
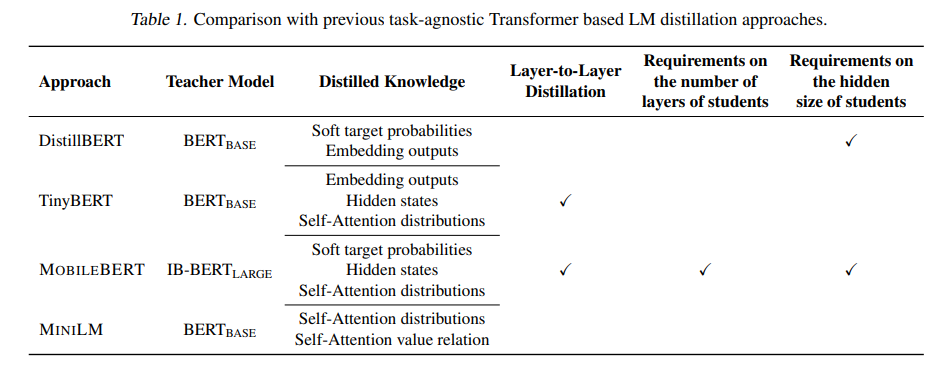
Transformer에서 feature KD는 teacher와 student사이의 self-attention을 비교하는 방식이 많이 사용되어 왔음
기존 방식들은 feature distillation의 경우 teacher, student layer 개수가 동일해야 되는 한계가 있었음
본 논문에서는 transformer의 마지막 layer만 비교함
추가적으로 value-relation도 같이 고려함
Proposed method

컨셉은 간단함.
self-attention map에 대한 KL-Divergence 진행
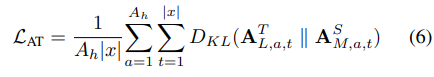
value-relation (value에 대한 gram matrix와 유사) 에 대한 KL-Divergence 진행

self-attention을 비교하게 되면 더이상 student의 channel size를 신경쓸 필요가 없음
(보통의 feature distillation에서는 teacher와 student의 channel를 맞춰주기 위해 1x1 conv와 같은 transformation이 필요했음)전체 loss
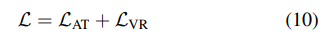
추가적으로 teacher-assistant를 두어 teacher와 student사이의 bridge 역할을 함
Experiment result

동일 파라미터에서 좋은 성능을 보여줌

Teacher assistant가 성능 향상에 도움이 됨

value-relation에 대한 효과

layer-to-layer보다 마지막 layer만 비교하는게 성능이 좋음
(teacher와 student layer 개수가 다른 경우 uniform strategy로 매칭 시켜주는 것 같음)
'Contribution 세미나' 카테고리의 다른 글